深度神经网络入门
人工智能已经火过一波又一波,事实上现在用的一些技术早在十几甚至几十年前就已经发明和论证过,只是当时算力和数据有限,无法发挥出作用,技术“也要考虑到历史的行程”。随着算力的提升,以及大量有价值数据的积累,人工智能技术在生活中的应用越来越普及,在图像识别、语音识别等传统程序无法解决的领域大放异彩,其中深度神经网络技术起了至关重要的作用,作为机器学习中的精华,不管是休闲娱乐(搞点好玩的应用)还是居家防身(改行跳槽之类),非常有必要学习一下。这篇文章主要讲解深度神经网络的简单原理,由于本人也是初步学习,此文算是一个阶段性学习总结,难免有错误,还请大家批评指正。
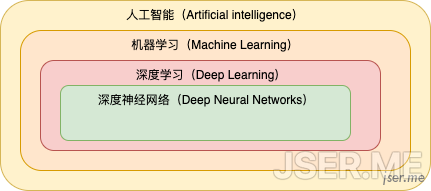
一下就抛出了好几个比较热门的名词,这些名词到底啥意义,是什么关系?其实一张图就能说明:
我们先从最简单的预测机来谈起
简单预测器
假设我们现在有一台美元到人民币的转换机,给它塞美元,自动出人民币,我们想知道它内部转换的公式,现在塞 1 美元,它出 7.15 人民币。
$=w¥请忘记你会解一元一次方程组,用最原始的方法来求解 w,我们先随机设一下 w 为 5,结果是 5, 误差为 2.15,比较大;设 w 为 10,误差为 -2.85,有点过大了,需要往小了调 w,假设我们经过了下面这样的调整过程
| w | 误差 | w增加值 |
|---|---|---|
| 5 | 2.15 | null |
| 10 | -2.85 | 5 |
| 6 | 1.15 | -4 |
| 7 | 0.15 | 1 |
| 7.1 | 0.05 | 0.1 |
| 7.2 | -0.05 | 0.1 |
| 7.15 | 0 | -0.05 |
可以看到我们通过逐步调整 w,最终误差为 0,找到了正确的 w=7.15。对于一个新的输入,比如 4,就能预测出返回的是 28.6,对应的方程就是 y=7.15x,展示为图形:
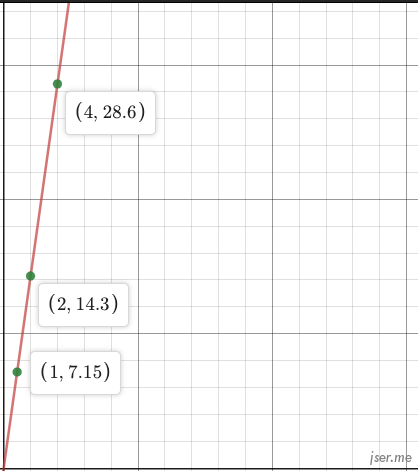
这条直线就可以理解为一个简单的预测器,给定一个输入 x,就能得到一个预测值 y。
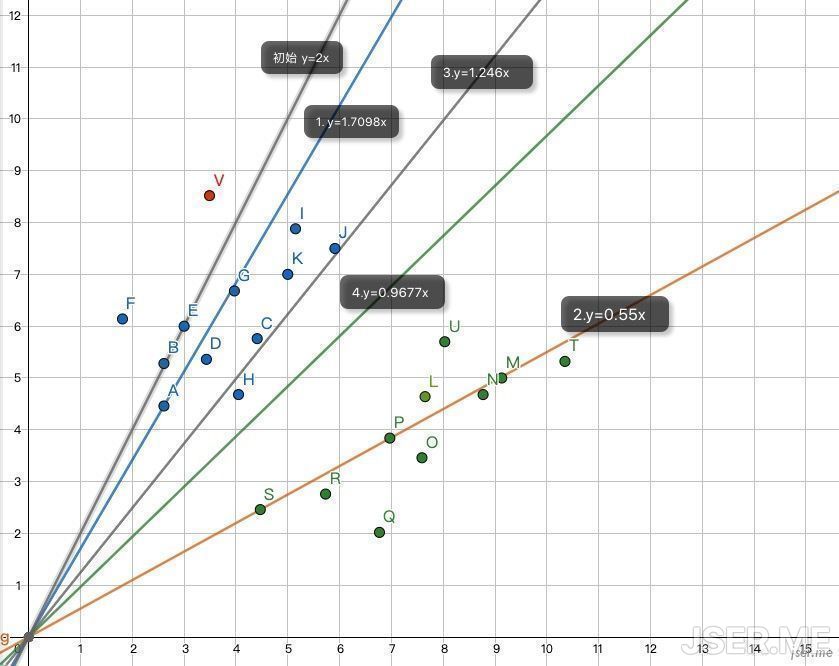
另外一种常见的任务是分类,比如已知两种物体的宽度和长度,给定一个新的宽度和长度,确定出它是哪种物体。把宽度长度分别当作 x 和 y,在坐标系里画出散点图,观察发现画一条直线就能把两种类别分开,新的点,比如图中的红点 V,把它的 x = 3.49 代入直线的方程 y=0.9677x,得到 y = 2.6999,V 的实际 y = 8.52,大于直线方程所得的y值,所以它属于蓝色的物体,也就是说一条直线也是可以用来分类。
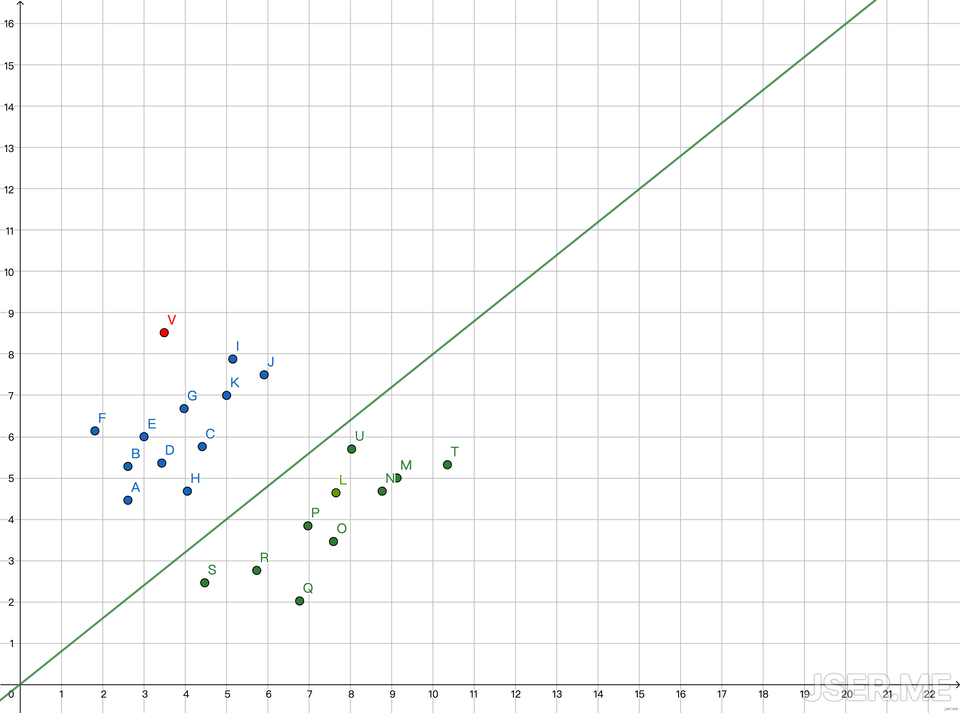
这个分类器里的 0.9677 是怎么算出来的呢? 跟上面预测值的方式类似,这次我们取图中两个点 A 和 S
| 点 | 宽 | 长 | 类别 |
|---|---|---|---|
| A | 2.61 | 4.46 | 蓝 |
| S | 4.47 | 2.46 | 绿 |
直线的公式是 y=ax+b ,依然使用简化形式,忽略 b,误差 E 和 a 变化之间的关系如下,这几个公式极其简单:
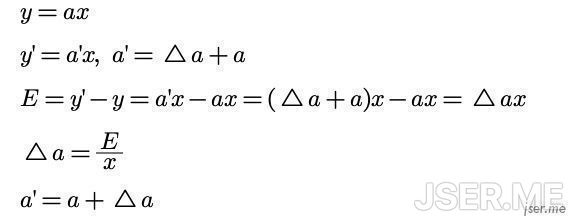
我们随机取一个 a=2,对于 A,E = 4.46- 2 * 2.61 = - 0.76,下一次的 a 应该是 a’ = a + E/x = 2 + (-0.76/2.61) = 1.7098,这时候可以完美穿过 A 点;接下来我们使用 S 点,E = 2.46 - 1.7098 * 4.47 = -5.1828,新的 a 为 a’ = 1.7098 + (-5.1828/4.47) = 0.55,可以看到新的黄线完美穿过了 S,但是一部分点还是错误的,比如 U 和 L;这时候我们需要引入一个学习率L(learning rate),也就是从 A 到 S 的过程,不要一步到位,一点一点的走。
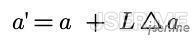
比如我们随机定 L=0.4,对于S,新的a为a’= 1.7098 + 0.4*(-5.1828/4.47)=1.246,这条线还是不能很好的把点区分开,比如 H 点,我们继续代入 S 点,E = 2.46 - 1.246 * 4.47 = -3.1096,a’ = 1.246 + 0.4 * (-3.1096/4.47) = 0.9677,可以看到这条新线是可以很好的把两个分类区分开来。
如下图1,2,3,4所示,我们一步一步的找到了正确的直线来分类这蓝点与绿点
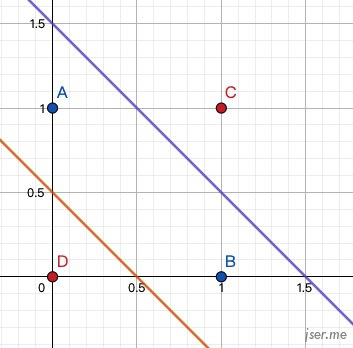
小结一下,可以看到不管是预测值还是分类,对于这种线性的数据,一条直线就可以解决问题。我们有一些数据,包含了输入与输出,需要找到一个f(x)的定义,能描述出输入与输出的关系,这里我们是直接观察数据是线性的,所以用线性方程来描述,然后一步一步的通过误差来调整得到 a 的值,这其实就是机器学习的基本过程。然而现实情况会更复杂,比如经典的 XOR 问题,对于布尔运算异或的定义是两个操作数,有且只有一个为真是,结果为真,否则为假。
1 ^ 0 = 1
0 ^ 1 = 1
0 ^ 0 = 0
1 ^ 1 = 0如果画图的话,需要两个线性分类器才能完美解决,如图:
这种需要多个分类器组合的情况怎么办呢?我们先来看看神经网络的基本单元,神经元
神经元(感知机)
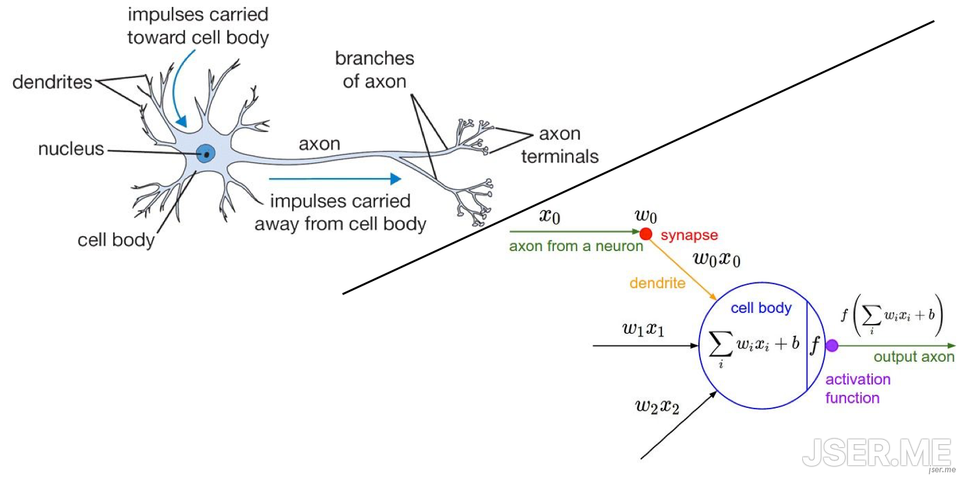
深度神经网络模拟生物神经网络,由神经元组成,一个生物神经元结构如下
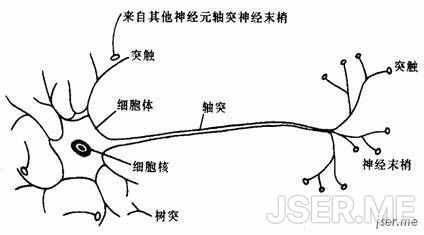
可以看到神经元中细胞周围有多个放射状树突,每个神经元有一个细长而均匀的突起结构,叫轴突。轴突末端的分支,叫轴突末梢。每个神经元从树突接收输入信号,某时刻累计信号超出某阈值时,通过轴突释放传出。轴突末梢连续其它神经元树突,形成神经网络。
模拟单个神经元的模型叫感知机,也是深度神经网络的基本结构,如图:
它的数学公式表达为:
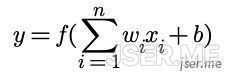
可以看到感知机接收 n 个输入,经过加权相加,以及添加一个偏移b,最后通过一个函数判断阈值,也有类似神经元的信号累积达到某个值的时候才输出机制,这个函数我们称为激活函数(activation function),比较常用的是 relu 和 sigmod,它们的函数图像如下:
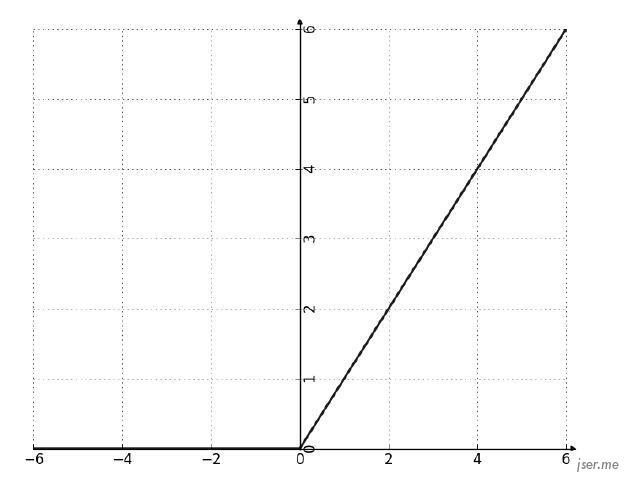
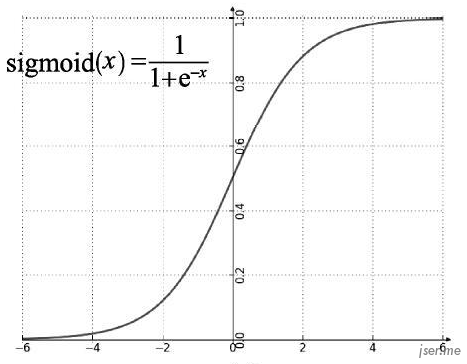
单个感知机能做的事情和前面的简单预测器类似,能解决简单的线性问题,只有当它们互相连接形成网络时才能解决更复杂的非线性问题。一般把它们连成的网络叫神经网络,也叫多层感知机。
神经网络(多层感知机)
我们首先来看一个 2x2 的两层感知机,如图
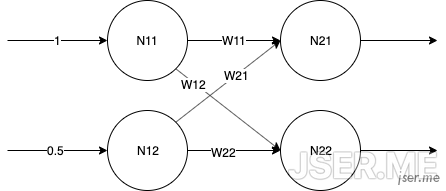
第一层接收输入后不做处理,权重我们随机出来,[W11, W12, W21, W22] = [0.3,0.4,0.2,0.1],第二层的b随机为b21=2, b22=3,第二层收到后,按单个感知机计算得出
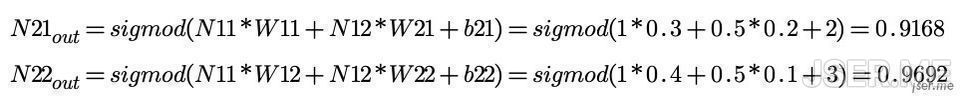
像简单预测器那样我们知道输入输出的话,如何把最终的误差反馈来调节 W 呢?这就需要用到反向传播
反向传播算法
我们以 xor 为例,上面的2x2感知机相当于只有输入和输出,除了输入和输出层之外的层可以称之为隐藏层,现在我们来定义一下输入层有两个神经元,隐藏层有两个神经元,输出层有一个神经元的神经网络:
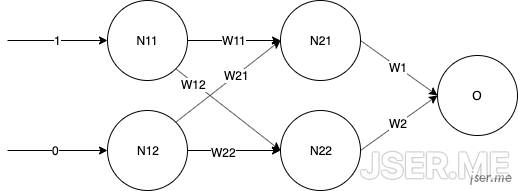
新增加的隐藏层到输出层的[W1,W2]=[0.2,0.4],输出层的b随机为4,这些都是随机弄出来的
重新计算的N21和N22为:
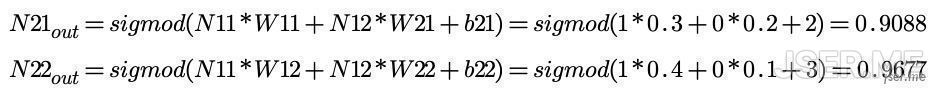
计算的输出为
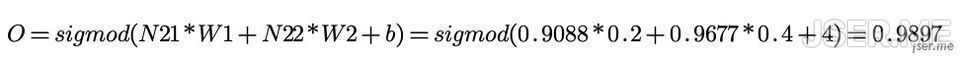
书写方便的话,可以用矩阵来表示,注意偏置b和输入矩阵最后一行的1是为了计算正确,隐藏层和输出层可以表示为:
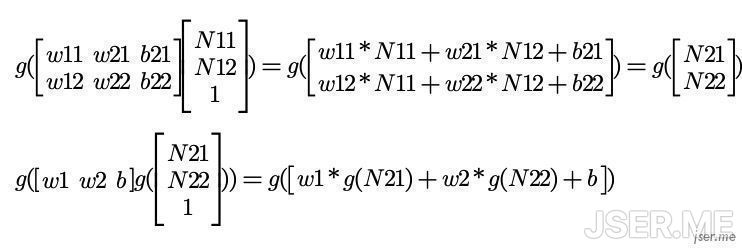
这个计算过程也叫做正向传播。
1^0=1,目标的数据应该是1,在简单预测器里我们使用的简单的差来评估误差,这里我们来使用差的平方1/2(目标值-计算值)^2(1/2是为了后面计算方便),这个评估误差的函数也叫损失函数或者代价函数(loss function),训练调整w的目标是使用误差最小,也就是误差函数的值趋于0,从前面的计算可以看出,所有的 w 都和误差相关,那我们应该怎么找到使误差最小的每一个 w 的值呢?
我们可以使用梯度下降法来求函数最小值。我们来推导一下反向传播算法的公式,根据微分的链式法则,我们先来求出 w1 应该更新的公式:
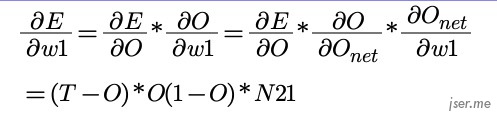
最终新的 w1’ 应该为 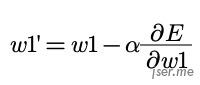 ,如果按矩阵表示,激活函数为 sigmod 的神经网络第 j 层到第 k 层的权重变化矩阵为:
,如果按矩阵表示,激活函数为 sigmod 的神经网络第 j 层到第 k 层的权重变化矩阵为:
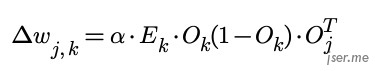
实际使用的过程中,框架会自动计算,我们以一段 Node 的 tensorflow.js 代码展示:
const tf = require('@tensorflow/tfjs-node')
const model = tf.sequential()
model.add(tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' }))
model.add(tf.layers.dense({ units: 1, activation: "sigmoid" }))
model.compile({ optimizer: tf.train.sgd(0.5), loss: 'meanSquaredError' });
const data = tf.tensor([[0, 0], [0, 1],[1, 1], [1, 0]])
const target = tf.tensor([0, 1, 0, 1], [4, 1]);
(async function () {
await model.fit(data, target, {
batchSize: 3,
epochs: 3000,
callbacks: tf.node.tensorBoard('./fit_logs_1')
})
const predict1 = await model.predict(tf.tensor([0, 0], [1, 2])).data()
console.log(`0, 0 : ${predict1}`)
const predict2 = await model.predict(tf.tensor([1, 0], [1, 2])).data()
console.log(`1, 0 : ${predict2}`)
})()
/*
输出:
0, 0 : 0.04225059226155281
1, 0 : 0.9512262940406799
*/这段代码构建的网络结构与前面我们画的网络结构一致,最后结果输出符合预期。
卷积神经网络
使用梯度下降法的全连接网络可以从大量数据中学习非线性特征,但是在图片或者音频处理方面,单个图片像素一般比较大,如果依然直接使用全连接网络,权重的数量非常庞大,对于训练和模型的实际使用都变得不太现实,而深度学习最成功的领域就是图像,下面简单介绍一下图像处理里最基础的结构:卷积神经网络。
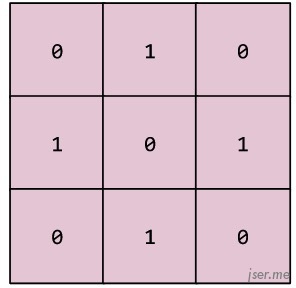
首先卷积是什么?它是一种运算,可以把卷积核看作是一个滤波器,被卷积数据在卷积核上的响应。如下是一个3x3的卷积核:
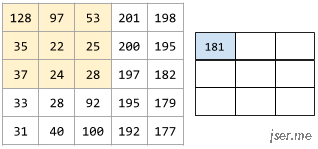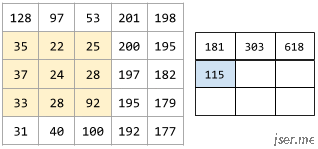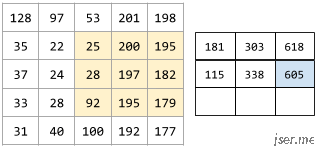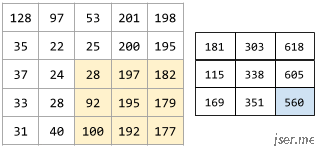
下面的动画显示了一个由 9 个卷积运算(涉及 5x5 输入矩阵)组成的卷积层。请注意,每个卷积运算都涉及一个不同的 3x3 输入矩阵切片。由此产生的 3×3 矩阵(右侧)就包含 9 个卷积运算的结果:
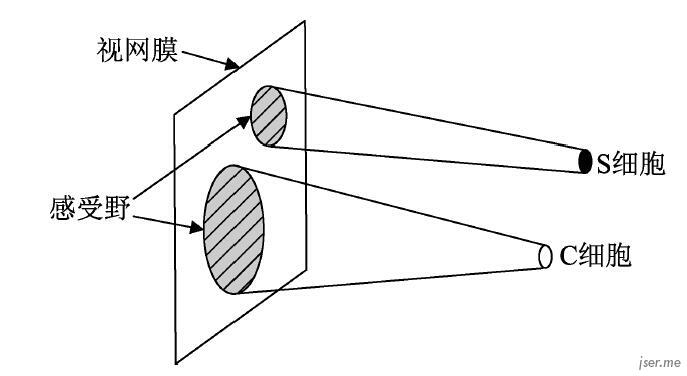
卷积神经网络是受视觉皮层启发,视觉皮层有两种细胞,简单细胞和复杂细胞,这两种细胞只对特定方向的条形图样刺激有反应,也就是说这些细胞是有方向选择性的。主要区别是简单细胞对应的视网膜上的光感受细胞所在的区域很小,而复杂细胞对应更大的区域,这个区域稍作感受野。卷积神经网络用卷积层来模拟对特定图案的响应,用池化层模拟感受野。
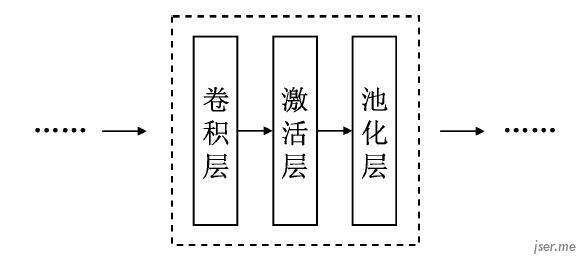
卷积神经网络一般结构:
同样以 tensorflow.js 识别 mnist 数据集的模型为例:
const tf = require('@tensorflow/tfjs');
const model = tf.sequential();
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
filters: 32,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.conv2d({
filters: 32,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2]}));
model.add(tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2]}));
model.add(tf.layers.flatten());
model.add(tf.layers.dropout({rate: 0.25}));
model.add(tf.layers.dense({units: 512, activation: 'relu'}));
model.add(tf.layers.dropout({rate: 0.5}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
model.compile({
optimizer: 'rmsprop',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
module.exports = model;这个网络是 两个卷积层 -> 池化层 -> 两个卷积层 -> 512 神经元的全连接层 -> 10个神经元的输出层,因为最后要输出的是分类数据,最后用了 softmax 作为激活函数。
总结
本文只是粗浅的介绍了一些深度神经网络的知识点,实践中使用还需要大量的学习与实践,类似于实践过程中的梯度消失与爆炸,准备数据与调参经验等,待日后再此文继续补上。