又双叒叕折腾一下 Blog
起因
上一次折腾 Blog 已经是十多年前了,沧海桑田,前端已经从一个朝阳职业,变成“快没了”的行业,我也早不再是一个单纯的“前端工程师”,这次换 Blog,一方面是尝试一些新的技术栈,另一方面也准备重新开始在 Blog 写点东西。
为什么要在 Blog 写东西呢,公众号、头条、小红书等平台既有自然流量编辑体验也凑合,为什么还要单纯搭建一个 Blog 呢?其实没什么特别的,有点闲,顺手尝试尝试,平台远没有自己弄的东西舒服,比如阅读时字体、颜色、分段的体验,写作时不能充分使用 markdown,并且还有猜不透说不明的奇怪政策,找一个可以长期保存记录的地方,还是自己来更可靠。
目标
- 静态站点生成系统
- 旧内容以及旧链接迁移
- 历史功能平移
静态站点生成系统选择
粗看了一下几个比较热门的静态站点系统,最后选了 astro,有以下几个特点
- JS 写的,开源,且社区活跃,star 数量、仓库活跃度、社区生态都非常不错,不会是一个烂尾项目
- 纯静态输出,部署友好,不过分依赖服务器资源
- UI框架无关,可以支持React\Svelte\Vue,虽然现在主要还是使用React,保不准某天对其它框架有兴趣,保留一些可能性;同时对于这种UI无关的渲染也比较好奇它的实现,之前做的页面渲染系统还没有过渡到UI无关,可以了解一下
- 支持 MDX 直接在 markdown 里写组件,创建交互更强的 Blog 内容
迁移
下面是一些简单的记录以及一些功能改造
从模板开始
Astro自带了一些模板,同时命令行开始的体验也不错,开箱即用。用了一个最简单的 Blog 的模板,本地的所有文件就初始化完成了
npm create astro@latest -- --template blog文章迁移
历史 Blog 里的文章不多不少,手工迁移时间太久,实在不符合工程师的风格,原始 Blog 里主要也是 markdown 格式,主要是需要添加一些 meta 信息,如下
---
title: 一个标题
description: 一点点描述
pubDate: 2024-08-26 16:28:22
---历史 Blog 里的信息还有一些需要删除,比如 layout 这种,一开始测试的时候用本地的 LLM 直接对话对一个文章修改,使用了 chat 的形式,一步一步进行下面几步
tasks = [
"""
如果内容的meta信息里有date字段,将其格式化为 "YYYY-MM-DD" 格式,以pubDate这个字段插入到文件内容的meta信息里
如果没有请从文件名中提取第一个日期,将日期格式化为 "YYYY-MM-DD" 格式,以pubDate这个字段插入到文件内容的meta信息里
只返回meta部分的信息
""",
"""
如果meta里的tags为空或者不存在,总结文件内容中的tags,插入到meta信息里,格式如下 `tags: ["tag1", "tag2"]`
只返回meta部分的信息
""",
"""
如果description为空,简明扼要的总结**内容**出一个简介,插入到meta信息里,注意需要以第一人称的方式描述
只返回meta部分的信息
""",
"""
如果meta里有 `layout`字段,移除 meta 里的 `layout` 字段
如果meta里有 `date`字段,移除 meta 里的 `date` 字段
请返回处理后的完整markdown文件内容,不要有其他额外的输出
""",
]这个处理方式的问题是,响应比较慢,本地跑的 LLM 经常是在 10s 以上才有响应,效率实在是太低,这还是在特意添加了只返回meta部分信息控制了输出 token 的情况下,PS: 使用 ollama 测试了国内国外多个7B左右的模型,最好用的还是llama3.1:8b和gemma2:9b,其它模型经常是后面响应不再跟随指令或者开始完全胡说。
既然直接使用LLM来处理文件不太高效,还是使用传统的 yaml 解析处理的方式,对于 tags 和 description 的生成使用 LLM 来处理,LLM为了效率更高,使用了 Groq 上的 gemma2-9b-it
解析 yaml 核心代码如下:
def extract_yaml_meta(content):
yaml_pattern = re.compile(r"^---\s*\n(.*?)\n---\s*\n", re.DOTALL)
match = yaml_pattern.match(content)
if match:
yaml_content = match.group(1)
main_content = content[match.end() :]
return (yaml.safe_load(yaml_content), main_content)
return None提取文章的tags和description:
...
prompt = get_prompt(
"""提炼出最能代表内容tags,tags以,分隔,注意只返回以,分隔的tags字符串,不要换行,单行输出,单个tag尽量简洁,不可以是句子,tags数量不要超过5个""",
filename,
filecontent,
)
tags_str, total_duration = groq_single_generate(prompt)
print(f"llm return {tags_str} cost: {total_duration}")
# 合并且去重 tags
tags.extend([tag.strip() for tag in tags_str.split(",")])
tags = list(set(tags))
meta["tags"] = tags
# description
prompt = get_prompt(
"""总结内容,以简明扼要的方式概述内容
内容要求:
* 尽可能简短
* 返回为简体中文
* 内容文本数量不要超过100字
返回格式要求:
* 禁止出现“这是”“这篇”等无意义的词,
* 禁止出现“作者”,“文章”这类主语,
* 不要换行,单行输出,只返回描述字符串,
""",
filename,
filecontent,
)
des_str, total_duration = groq_single_generate(prompt)
print(f"llm return {des_str} cost: {total_duration}")
meta["description"] = des_str
...历史链接转换
历史 Blog 的链接形如 https://jser.me/2016/09/29/bash的各种文件执行顺序,为了兼容历史链接,保证别人在使用旧链接依然可以访问到以前内容,使用astro的路由功能,在pages下新建目录

在处理请求的[title].astro里,生成所有会访问到的路径参数,同时使用 Astro.rewrite 把内容重新定向到新路由 /blog/atricle/xxxx,这样就完成了历史路径的完全兼容
---
import { getCollection } from "astro:content";
export async function getStaticPaths() {
const postsByTag = new Map();
const reg = /^(\d{4})-(\d{2})-(\d{2})-(.+)$/;
const posts = await getCollection("blog");
const results: { params: { year: string; month: string; day: string; title: string } }[] = [];
for (const post of posts) {
if (!post.slug) continue;
if (!reg.test(post.slug)) {
continue;
}
const match = post.slug.match(reg);
if (!match) {
continue;
}
const [_, year, month, day, title] = match;
results.push({
params: {
year,
month,
day,
title,
},
});
}
return results;
}
const { year, month, day, title } = Astro.params || {};
return Astro.rewrite(`/blog/article/${year}-${month}-${day}-${title}`);
---历史静态文件支持
历史Blog里有一些演示类的文件,比如 这个,好在 Astro 作为一个静态站点工具,对于 public目录里的东西,是可以直接访问的,只需要把原来 demos 目录复制到 public 目录,就可以正常访问。
博客列表页
列表页就是所有博客按固定分页展示的地方,实现比较简单,按 Astro 官方的分页搞一下就成了,核心就是使用 getCollection 后排序,然后使用paginate处理一下
路由为 /blog/page/[page] 这样,核心处理代码
import { BLOG_PAGE_SIZE } from "../../../consts";
import { getCollection } from "astro:content";
export async function getStaticPaths({ paginate }) {
const posts = (await getCollection("blog")).sort(
(a, b) => b.data.pubDate.valueOf() - a.data.pubDate.valueOf()
);
const rst = paginate(posts, { pageSize: BLOG_PAGE_SIZE });
return rst;
}
const { page } = Astro.props;博客详情页
详情页路由为 /blog/article/[...slug],同样是使用getCollection获取整个集合,然后使用 slug 作为params过滤出当前内容,同时使用findIndex 来获取上一个文章和下一个文章
核心代码如下
---
export async function getStaticPaths() {
const posts = await getCollection("blog");
return posts.map((post) => ({
params: { slug: post.slug },
props: post,
}));
}
async function getNearPosts(slug: string) {
const posts = await getCollection("blog");
const currentPostIndex = posts
.sort((a, b) => b.data.pubDate.valueOf() - a.data.pubDate.valueOf())
.findIndex((post) => post.slug === slug);
const prevPost = posts[currentPostIndex - 1];
const nextPost = posts[currentPostIndex + 1];
return { prevPost, nextPost };
}
const post = Astro.props;
const { Content } = await post.render();
const { prevPost, nextPost } = await getNearPosts(post.slug);
---评论
老版的博客曾经放弃了评论,作为一个反馈的渠道,新博客还是加一下,使用了 giscus,它本质上是使用 github 仓库的 discussions 作为存储
按照 giscus 的说明,配置一下仓库就能得到一段可用的JS,然后放到详情页里就可以每次展示了
Tag相关
Tag 作为内容一种分类方式,还是有支持的必要的,在经过 LLM 处理后所有文章都有 tag,可以很方便的进行检索,这里要做的就是聚合展示 tag 页和单个 tag 对应的文章列表页,同样是使用 getCollection 然后处理后得到这两种页面的数据
路由如下:
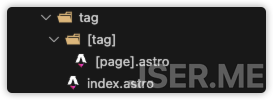
index.astro是聚合页,[tag]/[page].astro是单个 tag 对应的文章列表页,核心处理数据代码如下,本质上它是在遍历所有 Tag + 页码 的页面路径组合:
---
import { getCollection } from "astro:content";
export async function getStaticPaths({ paginate }) {
const postsByTag = new Map();
(await getCollection("blog")).forEach((post) => {
if (!post.data.tags) return;
for (const tag of post.data.tags) {
if (!tag) continue;
const trimedTag = tag.trim();
if (postsByTag.has(trimedTag)) {
const old = postsByTag.get(trimedTag);
postsByTag.set(trimedTag, {
count: old.count + 1,
posts: [...old.posts, post],
});
} else {
postsByTag.set(trimedTag, {
count: 1,
posts: [post],
});
}
}
});
const result = [...postsByTag.entries()]
.map(([tag, { count, posts }]) => {
posts.sort((a, b) => b.data.pubDate.valueOf() - a.data.pubDate.valueOf());
return paginate(posts, {
pageSize: BLOG_PAGE_SIZE,
params: { tag: tag },
props: { tag, count },
});
})
.flat();
return result;
}
const { page, tag, count } = Astro.props;
---增加搜索
使用 pagefind 作为搜索引擎,pagefind 是一个 Rust 写的纯静态搜索引擎,它在本地进行索引,搜索也是纯浏览器端 JS 实现,没有服务器端的消耗,非常适合静态站点。
使用方法也非常简单,安装好 npm 包之后,在 postbuild 里添加上索引生成的脚本,每次发布站点的时候主动索引一次就行
"postbuild": "pagefind --site dist --glob \"{blog/article,about}/**/*.html\"",这里指定了在 dist 目录里索引 blog/article, about两个路径下的所有html文件,对于中文支持,需要注意一下 html 标签的 lang 应该为 zh-cn,否则索引中文会有问题,导致无法搜索
<!doctype html>
<html lang="zh-cn">
<head>
...客户端就是一个搜索框,处理一下交互逻辑,初始化 pagefind,调用 pagefind 然后渲染结果就行,核心加载和调用如下
...
if (!window.pagefind) {
window.pagefind = await import("/pagefind/pagefind.js");
await window.pagefind.options({
excerptLength: 5,
highlightParam: "highlight",
});
}
const search = await window.pagefind.search(e.target.value);
...增加推荐
搜索功能完成后,构建一个简化的推荐就比较简单了,这里我们不考虑“反馈”,也就是不实时根据用户反馈进行推荐(毕竟咱内容量也太小了),每篇文章从整个集合里随机取几篇,同时使用当前文章的 tags 每个 tag 取几篇,合并去重,最后截取特定数量展示
推荐模块做成了一个Custom Element,如下:
---
import { getCollection } from "astro:content";
const posts = (await getCollection("blog"))
.sort((a, b) => b.data.pubDate.valueOf() - a.data.pubDate.valueOf())
.map((post) => ({
title: post.data.title,
slug: post.slug,
}));
const { post } = Astro.props;
const { slug } = post;
const { title, tags } = post.data;
---
<!-- Store the message prop as a data attribute. -->
<astro-recommander
data-post={JSON.stringify({ title, slug, tags })}
data-all-posts={JSON.stringify(posts)}
>
<div class="py-4">
<h3 class="text-xl font-bold mb-2">推荐文章</h3>
<ul class="list-disc list-inside text-base space-y-2">
<!-- <li><a href="">这是一个</a></li> -->
</ul>
</div>
</astro-recommander>
<script is:inline>
(() => {
const initAstroRecommander = async () => {
class AstroRecommander extends HTMLElement {
constructor() {
super();
this.post = JSON.parse(this.dataset.post);
this.allPosts = JSON.parse(this.dataset.allPosts);
this.prepare().then(() => {
this.genData();
});
}
async prepare() {
if (!window.pagefind) {
window.pagefind = await import("/pagefind/pagefind.js");
await window.pagefind.options({
excerptLength: 5,
highlightParam: "highlight",
});
}
}
async genData() {
const maxRandomCount = 3;
const maxSearchItemCount = 5;
const maxRecommandItemCount = 5;
// 随机取
const randomArticles = this.allPosts
.filter((article) => article.slug !== this.post.slug)
.map((article) => ({
title: article.title,
url: `/blog/article/${article.slug}`,
}))
.sort(() => Math.random() - 0.5)
.slice(0, maxRandomCount);
// 根据tag搜索
const searchResults = [];
if (this.post.tags) {
for (const tag of this.post.tags) {
const search = await window.pagefind.search(tag);
if (search.results.length > 0) {
for (const result of search.results.slice(0, maxSearchItemCount)) {
const data = await result.data();
if (data.meta.title !== this.post.title) {
searchResults.push({
title: data.meta.title,
url: data.url,
});
}
}
}
}
}
// 合并
const combined = searchResults.concat(randomArticles);
const result = combined
// 去重
.filter((v, i, a) => a.findIndex((t) => t.title === v.title) === i)
// 随机
.sort(() => Math.random() - 0.5)
.slice(0, maxRecommandItemCount);
this.querySelector("ul").innerHTML = result
.map((article) => `<li><a href="${article.url}">${article.title}</a></li>`)
.join("");
}
}
customElements.define("astro-recommander", AstroRecommander);
};
window.addEventListener("DOMContentLoaded", initAstroRecommander, { once: true });
})();
</script>核心逻辑就是 getData 里的过程
样式改造和响应式
为了方便样式处理,引入tailwindcss,astro 对 tailwindcss 支持非常好
npx astro add tailwind一行命令就可以支持,接下来就可以高效的使用 tailwind 的大量高效的工具类了
接下来就可以使用 md:xx 来做响应式的处理,由于样板工程本身就是响应式的,需要改造的地方并不多,只是针对导航做了一些处理,小屏的时候导航直接换行展示,大屏的时候不换行且展示联系方式的 Logo
外部链接小图标展示
对于链接添加一个小图标,当前 当前站点 的链接则不添加
@reference "tailwindcss"
.markdown-body a[href^="http://"]::after,
.markdown-body a[href^="https://"]::after
{
@apply w-3 h-3 ml-1 bg-no-repeat bg-center bg-contain inline-block;
content: "";
background-image: url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' width='16' height='16' fill='currentColor' viewBox='0 0 16 16'%3E%3Cpath fill-rule='evenodd' d='M8.636 3.5a.5.5 0 0 0-.5-.5H1.5A1.5 1.5 0 0 0 0 4.5v10A1.5 1.5 0 0 0 1.5 16h10a1.5 1.5 0 0 0 1.5-1.5V7.864a.5.5 0 0 0-1 0V14.5a.5.5 0 0 1-.5.5h-10a.5.5 0 0 1-.5-.5v-10a.5.5 0 0 1 .5-.5h6.636a.5.5 0 0 0 .5-.5z'/%3E%3Cpath fill-rule='evenodd' d='M16 .5a.5.5 0 0 0-.5-.5h-5a.5.5 0 0 0 0 1h3.793L6.146 9.146a.5.5 0 1 0 .708.708L15 1.707V5.5a.5.5 0 0 0 1 0v-5z'/%3E%3C/svg%3E");
}
.markdown-body a[href^="https://jser.me"]::after
{
@apply hidden;
}代码块展示对应的语言
代码块渲染输出的时候会有属性 data-lang,可以使用 css 利用这个属性在代码块右上角展示语言
.markdown-body .astro-code {
@apply relative pt-10;
}
.markdown-body .astro-code::before {
content: attr(data-language);
@apply absolute text-sm font-semibold top-0 left-0 px-4 py-2 text-white uppercase;
}照片/图片 处理
对所有图片处理,有以下几个需求
- 去除 EXIF 信息
- 图片设置宽度最大 960
- 所有图片添加水印
使用 JS 库 sharp 对所有图片进行处理,同时维护一个文本列表,记录所有处理过的图像,如果处理过,就不二次处理了,具体代码如下,比较长但是实很简单,主要是一些错误处理使过程显得很长
import fs from 'fs';
import path from 'path';
import sharp from 'sharp';
import { fileURLToPath } from 'url';
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
const publicImagesDir = path.join(__dirname, '../public/images');
const fileStatesTxt = path.join(__dirname, '../public/file_states.txt');
const MAX_WIDTH = 960;
const WATERMARK_WIDTH = 150;
const watermarkPath = path.join(__dirname, 'watermark.png');
const outputDir = path.join(__dirname, '../public/images_bak');
fs.rmSync(outputDir, { recursive: true, force: true });
fs.mkdirSync(outputDir);
if (!fs.existsSync(fileStatesTxt)) {
fs.writeFileSync(fileStatesTxt, '');
}
(async () => {
// Get all image files in the public directory
const files = await fs.promises.readdir(publicImagesDir);
const imageFiles = files.filter(file => {
const ext = path.extname(file).toLowerCase();
return [ '.jpg', '.jpeg', '.png', '.gif' ].includes(ext);
});
// Read the file states
const fileStates = fs.readFileSync(fileStatesTxt, 'utf8').split('\n');
// Process each image file
for (const file of imageFiles) {
const inputPath = path.join(publicImagesDir, file);
const outputPath = path.join(outputDir, file);
// copy if the file has been processed
if (fileStates.includes(file)) {
fs.copyFileSync(inputPath, outputPath);
console.log('Copied image:', file);
continue;
} else {
console.log('Processing image:', file);
const { width } = await sharp(inputPath).metadata();
// Remove EXIF metadata and resize if necessary
const image = await sharp(inputPath)
.rotate()
.resize({ width: MAX_WIDTH, withoutEnlargement: true })
.toBuffer();
const watermark = await sharp(watermarkPath)
.resize({ width: Math.min(WATERMARK_WIDTH, Math.round(width / 2)) })
.extend({
top: 0,
bottom: 8,
left: 0,
right: 8,
background: { r: 0, g: 0, b: 0, alpha: 0 }
})
.toBuffer();
if (image.width < WATERMARK_WIDTH) {
fs.copyFileSync(inputPath, outputPath);
console.log('Copied image:', file);
} else {
await sharp(image)
.composite([ { input: watermark, gravity: 'southeast' } ])
.toFile(outputPath)
.then(info => {
// console.log('Processed image:', info);
})
.catch(err => {
console.error('Error processing image:', err);
});
}
// Record the file state
fs.appendFileSync(fileStatesTxt, `${file}\n`);
}
}
console.log('All images processed');
// Replace public/images with public/images_bak
fs.rmSync(publicImagesDir, { recursive: true, force: true });
fs.renameSync(outputDir, publicImagesDir);
console.log('Images moved to public/images');
})();加入到 package.json 的 postbuild 的命令里
"postbuild": "pagefind --site dist --glob \"{blog/article,about}/**/*.html\" && node ./script/modify_image.mjs",统计
jser.me的域名已经迁移到 cloudflare 上了,在 cloudflare 添加站点,它就会自动添加统计代码。
原理是它会在 body 结束之前动态添加一个标签,非常方便,不过功能上不如 Google Analytics 强大,当作一个简易的统计也基本可用
<script defer src="https://static.cloudflareinsights.com/beacon.min.js/vcd15cbe7772f49c399c6a5babf22c1" integrity="sha512-dKBHq9Md29nnaEIPlkf84rnaERnq6zvWvPUqr2ft8M1aS28oN72PdrCzSjY4U6VaAw1EQ==" data-cf-beacon='{"rayId":"f9c320ffb8bc668c","version":"2024.8.0","r":1,"token":"e82eae8ef40a7b892348c8cb18923b74e57b","serverTiming":{"name":{"cfL4":true}}}' crossorigin="anonymous"></script>部署
纯静态的部署,很多服务都支持,比较普遍的是用 github pages,但是 pages 在国内经常出问题,cloudflare 免费版已经够用,并且 astro 与它配合非常流畅,安装并且配置好 wrangler 之后,在 packages.json 里加上
"deploy": "npm run build && npx wrangler pages deploy dist"之后就每次发布只需要 npm run deploy 就行
写作体验优化
添加snippet
写的时候主要是使用vscode,快速添加 meta 信息
首先添加一个 meta 的 snippet,在.vscode目录里添加一个blog.code-snippets文件
{
"meta of blog": {
"prefix": "meta",
"scope": "markdown,md",
"body": [
"---",
"title: ${1}",
"description: ${2}",
"pubDate: ${CURRENT_YEAR}-${CURRENT_MONTH}-${CURRENT_DATE} ${CURRENT_HOUR}:${CURRENT_MINUTE}:${CURRENT_SECOND}",
"---"
],
"description": "meta data of blog"
},
"code": {
"prefix": "code",
"scope": "markdown,md",
"body": [
"```${1}",
"${2}",
"```"
],
"description": "markdown code block"
}
}对于高频使用的代码块也添加了一个 snippet,输入 code 的时候会自动提示
同时开启了 markdown 文件的自动提示,这样就不需要每次使用快捷键cmd+space添加snippet,输入meta的时候自动提示
在项目的.vscode目录里修改 settings.json,添加下面的配置
"[markdown]": {
"editor.quickSuggestions": {
"other": "on",
"comments": "on",
"strings": "on"
}
},粘贴图像
写文章的时候也需要处理一些图片,如果不处理的话,需要把图片移动到 public 目录,然后再在 markdown 里插入图片链接,而本地文件链接与线上展示链接又不一致,如果直接使用 vscode 自己的 markdown 编辑时粘贴配置,只能做到图片复制到指定地方,但是展示的路径还是本地文件路径,还需要再次修改展示路径才能在线上展示正常,幸好有人做了一个专门处理粘贴图像的插件。
Paste Image,专门用来解决这个问题,在项目的 .vscode/settings.json 里添加下面的配置项
"pasteImage.namePrefix": "${currentFileNameWithoutExt}_",
"pasteImage.path": "${projectRoot}/public/images",
"pasteImage.basePath": "/${projectRoot}",
"pasteImage.forceUnixStyleSeparator": true,
"pasteImage.prefix": "/"这段配置,可以帮助在粘贴图像的时候把图像保存到项目根目录的 public/images 目录下,同时展示出来的链接是 /public/images/filename_xxx.png 这种形式,可以做到只需要粘贴图像就行了。
发布前自动添加 tags 和 description
每次写文章的时候还要考虑加 tags 和 description 会减少一些写文章的乐趣,增加负担,这个过程可以复用迁移脚本里的逻辑,在 build 之前调用脚本来给文章生成 tags 和 description,在 package.json 里添加
"prebuild": "python ./script/gen_meta.py",这个脚本逻辑与迁移脚本逻辑一致,加了对于长文本的处理,切分为块,分块取 tag 和总结,最后再对 tag 统一去重,所有总结合并一起二次总结。
总结
整体上迁移还算顺利,想要的功能也都实现了,Astro 社区、文档都比较齐全,功能也非常灵活,非常适合快速做静态站点。以后可以愉快的在本地使用 vscode 快乐的写东西,然后无痛发布到线上了,谢谢 cloudflare 真赛博菩萨。